| Структура данных и алгоритмы на языке Pascal |
Динамическое распределение памяти
Разработка программы для компьютера в некотором смысле напоминает процесс составления проекта здания, включающий в себя рассмотрение многочисленных функциональных и эстетических вопросов, влияющих на окончательный результат. Например, некоторые программы имеют строгое функциональное назначение как дом, который имеет определенное число спальных комнат, кухню, две ванные комнаты и т.д. Другие программы носят менее завершенный характер, как центры для проведения собраний, которые имеют передвижные стены и модульные полы, позволяющие лучше приспособить здание для каждого конкретного случая. В этой главе описывается механизм управления памятью, позволяющий разрабатывать гибкие программы, которые могут адаптироваться к конкретным нуждам пользователя и возможностям ЭВМ.
Следует отметить, что в этой главе используется термин "логический массив" и термин физический массив". Логический массив - это такой массив, который представляется существующим в системе. Например, матрица на листе бумаги является логическим массивом. Физический массив - это массив, который в действительности имеется в вычислительной системе. Связь между двумя этими массивами обеспечивается программами по поддержке разреженных массивов. В этой главе рассматривается четыре метода создания разреженных массивов: посредством связанного списка, двоичного дерева, массива указателей и хеширования. Затем будут даны примеры динамического распределения памяти, которое позволяет повысить производительность программы.
В программе на языке Паскаль информацию в основной памяти ЭВМ можно хранить двумя способами. Первый способ заключается в использовании глобальных или локальных переменных, включая массивы и записи, которые предусмотрены в языке Паскаль. Глобальные переменные занимают постоянное место в памяти во время выполнения программы. Для локальных переменных память выделяется из стека ЭВМ. Хотя управление глобальными и локальными переменными на Паскале реализовано эффективно, программист должен знать заранее объем необходимой памяти для каждого конкретного случая. Другой и более эффективный способ управления памятью на Паскале обеспечивается применением функций по динамическому управлению памятью. Таким являются функции "New", "Dispose", "Mark" и "Release".
В обоих методах динамического управления памятью, память выделяется из свободного участка, который не входит в постоянную область программы, и стека /который используется в Паскале для хранения локальных переменных/. Эта область называется динамической (heap).
Рис.1 иллюстрирует структуру памяти для программы на языке Паскаль. Стек увеличивается в нижнем направлении. Объем памяти, необходимой стеку, зависит от характера программы. Например, программа со многими рекурсивными функциями будет требовать много стековой памяти, поскольку при каждом рекурсивном обращении выделяется участок стековой памяти. Участок выделяемой под программу и глобальные переменные памяти имеет постоянную величину и не изменяется во время выполнения программы. Память для запросов функции "New" берется из свободного участка памяти, который начинается сразу после глобальных переменных и продолжается до стека. В исключительных случаях может использоваться для стека область динамической памяти.
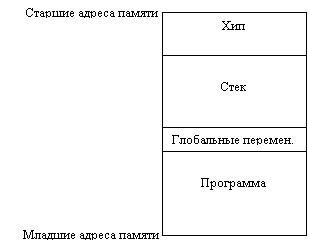 |
Рис.1. Использование памяти в программе на языке Паскаль.
Использование динамической памяти зависит от того, какая функция применяется для освобождения памяти и возвращения ее системе: функция "Dispose" или пара процедур "Mark" и "Release". Как указано в справочном руководстве по языку Паскаль, эти два способа нельзя никогда смешивать в одной программе. Следовательно, вам заранее необходимо решить, каким из способов пользоваться. Для того чтобы понять, чем эти способы отличаются друг от друга, ниже дается краткое описание этих функций.
ФУНКЦИЯ New
Использование этой функции позволяет получить память из динамической области. Эта встроенная процедура в качестве аргумента использует указатель на ту переменную, которая должна размещаться в динамической области. После обращения значение аргумента будет указывать на выделенный участок памяти. Например, для размещения вещественного числа в динамической области можно записать следующий код:
type rpntr = real; var p:rpntr; begin New(p); . . .
Если в динамической области не будет свободного участка, то будет выдан код ошибки FF /конфликт динамической области памяти или стека/. Для того, чтобы избежать этого, необходимо перед вызовом указанной функции сделать вызов функции "Max-AvatI", которая определяет размер в байтах незанятой части динамической области памяти. /Пользователи версии 3.0 должны иметь в виду, что указанная функция определяет число свободных блоков, а не байт/. В приведенном выше примере этот шаг отсутствует, но возможно он потребуется при решении ваших задач.
ФУНКЦИЯ Dispose
Одна из причин динамического распределения памяти заключается в возможности ее повторного использования. Один из способов возврата памяти в динамическую область предусматривает использование функции "Dispose". В качестве аргумента этой функции используется указатель, который применялся при вызове функции "New", т.е. эта функция использует указатель на участок, который действительно располагается в динамической области. После обращения к этой функции память, которая выделялась по заданному указателю, будет освобождена и может использоваться в дальнейшем. Например, ниже приводится короткая программа, которая динамически выделяет память под массив из сорока целых чисел и перед завершением возвращает занятую память системе:
{Динамическое выделение памяти с использованием функций New и Dispose.}
program Sample;
type
pntr = ^RecType;
RecType = array[1..40] of integer;
Var
p: pntr;
t: integer;
begin
New(p);
for t: = 1 to 40 do p^[t]: = t*2;
for t: = 1 to 40 do Write(p^[t], ' ');
WriteLn;
Dispose(p);
end.
ФУНКЦИИ Mark и Release
Альтернативой использованию функции Dispose является применение функций Mark и Release, которые совместно обеспечивают освобождение динамического участка памяти после его использования в программе. В действительности вызов функции Mark должен делаться до обращения к функции New, а вызов функции Release должен делаться после функции New, когда требуется перераспределить память. Функция Release освобождает все участки памяти, которые выделялись между вызовами функций Mark и Release. Таким способом системе возвращается несколько участков памяти, а при использовании функции Dispose возвращается только один участок памяти, задаваемый соответствующим указателем.
В функции Mark используется один аргумент. Он должен являться указателем переменной любого типа, поскольку единственным назначением этой функции является сохранением начала области памяти в динамической области. Функция Release должна использовать тот же указатель, который не должен модифицироваться. Например, в приведенной ниже программе выполняется динамическое выделение памяти под массив из сорока целых чисел и освобождение ее при помощи функций Mark и Release:
{Динамическое выделение памяти с использованием Mark и Release.}
program alloc;
type
pntr = ^RecType;
RecType = array[1..40] of integer;
var
p: pntr;
t: integer;
q: ^integer;
begin
Mark(q);
New(p);
for t: = 1 to 40 do p^[t]:=t*2;
for t:= 1 to 40 do Write(p^[t], ' ');
WriteLn;
Release(q);
{В этом месте вся память уже возвращена системе}
end.
Метод управления динамическим распределением памяти зависит от того, как вы хотите возвращать память системе. Если память будет возвращаться частично, то следует использовать функцию Dispose. Если вы всегда предполагаете освобождать всю память, то лучше использовать функции Mark и Release.
ОБРАБОТКА РАЗРЕЖЕННЫХ МАССИВОВ
Обработка разреженных массивов является основной областью применения динамического распределения памяти. В разреженных массивах фактически имеются не все элементы. Такой массив может потребоваться в тех случаях, когда размеры массива значительно превышают размер памяти машины и когда не все элементы массива будут использоваться. Массивы большой размерности требуют большого расхода памяти, поскольку ее объем растет по экспоненте в зависимости от размера массива. Например, для символьной матрицы 10x10 требуется только 100 байт памяти, а для матрицы 100x100 требуется 10 000 байт и для матрицы 1000x1000 требуется уже 1 000 000 байт памяти.
Электронная таблица является хорошим примером разреженной матрицы. Даже если матрица будет большой, например, 999x999, в каждый конкретный момент времени будет использована только некоторая ее часть. Каждому элементу электронной матрицы ставится в соответствие формула, значение или символьные строки. Память под каждый элемент разреженной матрицы выделяется по мере необходимости. Хотя использоваться может лишь небольшая часть элементов, вся матрица может быть очень большой - больше чем обычные размеры памяти ЭВМ.
Имеется три различных метода создания разреженных массивов: связанный список, двоичное дерево и массив указателей. Каждый из этих методов предполагает, что электронная матрица имеет форму, представленную на следующей странице.
В этом примере Х располагается в ячейке В2.
----А---- ----В---- ----С---- ...
1
2 Х
3
4
5
. . .
Использование связанного списка для организации разреженного массива
При реализации разреженного массива с помощью связанного списка формируется запись, которая содержит информационные поля для каждого элемента массива и поле позиции элемента в массиве, а также указатели на предыдущий и следующий элементы списка. Все записи в списке упорядочены по индексу массива. Доступ к элементам массива осуществляется путем прохода по связям элементов списка.
Например, может использоваться следующая запись для создания разреженного массива:
str128 = string[128];
str9 = string[9];
CellPointer = ^cell;
cell = record
CellName: str9; {содержит название ячейки}
formula: str128; {содержит формулу}
next: CellPointer; {указатель на следующую запись}
prior: CellPointer; {указатель на предыдущую запись}
end;
В этом примере поле "CellName" содержит строку с названием ячейки, например, А1, В34 или Z19. Строка "formula" содержит формулу для каждой ячейки электронной таблицы. Ниже приводятся несколько примерных программ, использующих разреженные матрицы на базе связанного списка. (Следует помнить, что имеется много способов реализации электронных таблиц. К приводимым ниже структурам данных и программам следует относиться только как к примерам использования таких методов). Для указателей начала и конца связанного списка используются следующие глобальные переменные:
start, last: CellPointer;
Когда вы вводите формулу в ячейку типичной электронной таблицы, вы фактически создаете новый элемент разреженной матрицы. Если электронная таблица строится на базе связанного списка, то вставка нового элемента будет производится с помощью функции "DLS Store". (Поскольку Паскаль позволяет создавать независимые функции указанная функция может использоваться фактически без всяких изменений). В приводимом примере список сортируется по названию ячейки (т.е. А12 предшествует А13 и т.д.)
{ упорядоченная вставка элементов в список и установка указателя на начало списка }
function DLS_Store(info, start: CellPointer; var last: CellPointer): CellPointer;
var
old, top: CellPointer;
done: boolean;
begin
top := start;
old := nil;
done := FALSE;
if start = nil then begin { первый элемент списка }
info^.next := nil;
last := info;
info^.prior :=nil;
DLS_Store := info;
end else
begin
while (start<>nil) and (not done) do
begin
if start^.CellName < info^.CellName then
begin
old := start;
start := start^.next;
end else
begin { вставка в середину }
if old <>nil then
begin
old^.next := info;
info^.next := start;
start^.prior := info;
info^.prior := old;
DLS_Store := top; { сохранение начала }
done := TRUE;
end else
begin
info^.next := start;{новый первый элемент }
info^.prior := nil;
DLS_Store := info;
done := TRUE;
end;
end;
end; { конец цикла }
if not done then begin
last^.next := info;
info^.next := nil;
info^.prior := last;
last := info;
DLS_Store := top; { сохранение начала }
end;
end;
end; { конец функции DLS_Store }
Для удаления элемента из электронной таблицы необходимо удалить соответствующую запись из списка и возвратить занимаемую им память системе с помощью функции Dispose. Функция DL_Delete удаляет ячейку из списка по заданному названию:
{ удаление ячейки из списка }
function DL_Delete(start: CellPointer; key str9): CellPointer;
var
temp, temp2: CellPointer;
done: boolean;
begin
if start^.CellName=key then
begin { первый элемент в списке }
DL_Delete := start^.next;
if temp^.next <> nil then
begin
temp := start^.next;
temp^.prior := nil;
end;
Dispose(start);
end else
begin
done := FALSE;
temp := start^.next;
temp2 := start;
while (temp<>nil) and (not done) do
begin
if temp^.CellName=key then
begin
temp2^.next := temp^.next;
if temp^.next<>nil then
temp^.next^.prior := temp2;
done := TRUE;
last := temp^.prior;
Dispose(temp);
end else
begin
temp2 := temp;
temp := temp^.next;
end;
end;
DL_Delete := start; { начало не изменяется }
if not done then WriteLn('not found');
end;
end; { конец процедуры удаления элемента из списка }
Функция Find позволяет обратиться к любой конкретной ячейке. Эта функция имеет важное значение, так как многие формулы электронной таблицы имеют ссылки на другие ячейки и нужно эти ячейки найти, чтобы обновить их значения. В этой функции используется линейный поиск и среднее число операций при линейном поиске равно n/2, где n является числом элементов в списке. Кроме того, значительные потери будут из-за того, что каждая ячейка может содержать ссылки на другие ячейки и тогда потребуется выполнить поиск этих ячеек. Ниже дается пример функции Find.
Создание, поддержка и обработка разряженных массивов имеет один большой недостаток, когда такой массив строится на базе связанного списка. Этот недостаток заключается в необходимости использовать линейный поиск каждой ячейки списка. Без дополнительной информации, которая требует дополнительного расхода памяти, нельзя обеспечить двоичный поиск ячейки. Даже процедура вставки использует линейный поиск для нахождения соответствующего места для вставки новой ячейки в отсортированный список. Эти проблемы можно решить, используя для построения разреженного массива двоичное дерево.
{ найти конкретную ячейку и установить указатель на нее }
function Find(cell: CellPointer): CellPointer;
var
c: CellPointer;
begin
c := start;
while c<>nil do
begin
if c^.CellName=cell^.CellName then find:=c
else c := c^.next;
end;
WriteLn('cell not found');
Find:=nil;
end; { конец процедуры поиска }
Использование двоичного дерева для организации разреженных массивов
Двоичное дерево является по существу модифицированным списком с двойной связью. Основное его преимущество над обычным списком является быстрота поиска элемента, и как следствие, быстрота вставок и просмотров. В тех случаях, когда требуется обеспечить быстрый поиск в связанном списке записей, применение двоичных деревьев дает очень хорошие результаты.
При использовании двоичного дерева для реализации электронной таблицы, запись "cell" следует изменить следующим образом:
CellPointer = ^cell; str9 = string[9]; str128 = string[128]; cell = record CellName: str9; formula: str128; left: CellPointer; right: CellPointer; end;
Функцию "Stree" можно модифицировать так, что дерево будет строиться по названию ячейки. Следует отметить, что параметр "New" является указателем на новый элемент дерева.
При вызове этой функции в качестве первых двух аргументов должен задаваться указатель корневой вершины, а в качестве третьего аргумента должен задаваться указатель на новую ячейку.
В качестве результата выдается указатель корневой вершины.
{ вставка ячейки в дерево }
function STree(root, r, New:CellPointer; data: char): CellPointer;
begin
if r = nil then
begin
New^.left := nil;
New^.right := nil;
if New^.Cellname < root^.Cellname
then root^.left := New
else root^.right := New;
STree := New;
end else
begin
if New^.Cellname<r^.Cellname then
STree := STree(r,r^.left, New)
else STree := STree(r, r^.right, New)
end;
Stree := root
end; { конец процедуры STree }
Для удаления ячейки из электронной таблицы следует модифицировать функцию Dtree, в качестве ключа используя название ячейки:
{ удаление элемента из дерева }
function DTree(root:Cellpointer;key:str9):Cellpointer;
var
temp,temp2:Cellpointer;
begin
if root^.CellName = key then
begin
if root^.left=root^.right tnen
begin
dispose(root)
DTree := nil;
end
else if root^.left=nil tnen
begin
temp := root^.right
dispose(root)
DTree := temp;
end
else if root^.right=nil tnen
begin
temp := root^.left
dispose(root)
DTree := temp;
end
else
begin { имеются два листа }
temp2 := root^.right
temp := root^.right
while temp^.left > nil do temp := temp^.left;
temp^.left := root^.left
dispose(root);
DTree := temp2
end;
else
begin
if root^.CellName < key
then root^.right := DTree(root^.right, key)
else root^.left := DTree(root^.left, key)
DTree := root;
end;
end; { конец функции DTree }
И наконец, можно модифицировать функцию поиска для быстрого нахождения ячейки по ее названию:
{ найти заданную ячейку и установить указатель на нее }
function Search(root: CellPointer; key str9): CellPointer
begin
if root:=nil then Search := nil
else begin
while (root^.CellName<>key) and (root<>nil) do
begin
if root^.CellName<>key then root:=root^.left
else root:=root^.right;
end;
Search := root;
end; { конец процедуры поиска }
Самым важным преимуществом двоичных деревьев над обычным связанным списком является значительно меньшее время поиска. Следует помнить, что при последовательном поиске в среднем требуется выполнить n/2 операций сравнения, где n является числом элементов в списке, а при двоичном поиске требуется выполнить только log2n операций сравнений.
Применение массива указателей для организации разреженных массивов
Предположим, что электронная матрица имеет размеры 26x100 /с А1 по Z100/ и состоит всего из 2 600 элементов. Теоретически можно использовать следующий массив записей:
str9 = string[9];
str128 = string[128];
CellPointer = CellPointer;
cell = record
CellName:str9;
formula:str128;
end;
var
pa:array[1..2600] of cell;
Однако, 2 600 ячеек, помноженные на 128 (размер одного поля для формулы), потребует 332 800 байт памяти под довольно небольшую электронную таблицу. Такой подход, очевидно, нельзя использовать на практике. В качестве альтернативы можно использовать массив указателей записей. В этом случае потребуется значительно меньше памяти, чем при создании всего массива. Кроме того, производительность будет значительно выше, чем при использовании связанного списка или дерева. Для этого метода данные описываются следующим образом:
type
str9 = string[9];
str128 = string[128];
cell = record
CellName:str9;
formula:str128;
end;
var
sheettarray[1..10000] of CellPointer;
Этот массив меньшего размера можно использовать для содержания указателей на информацию, введенную пользователем в электронную матрицу. При вводе каждого элемента указатель на информационную ячейку помещается в соответствующее место массива. Рис.2 иллюстрирует структуру памяти, когда разреженный массив строится на основе массива указателей.
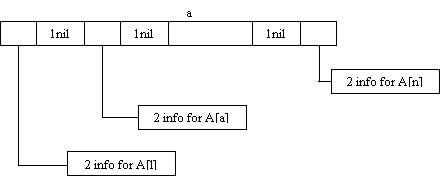 |
Рис.2. Использование массива указателей для организации разреженного массива: 1 - нулевое значение указателя; 2 - информационные поля соответствующего элемента.
Перед первым использованием массива указателей необходимо каждый элемент установить в нулевое значение, что означает отсутствие элемента в этой позиции. Используйте следующую функцию:
procedure InitSheet;
var
t:integer;
begin
for t := 1 to 10000 do sheet[t] := nil;
end; { конец блока инициализации }
Перед написанием процедуры вставки следует запрограммировать функцию поиска индекса. Эта функция находит соответствующий индекс массива указателей по заданному названию ячейки. При поиске индекса предполагается, что все названия начинаются с большой буквы, за которой идет некоторое число, например, В34, С19 и т.д.
Эта функция позволяет при реализации процедуры вставки соответствующую позицию массива указателей для каждой ячейки. Как видно, поиск нужного индекса выполняется просто и быстро, так как нет необходимости выполнять последовательный просмотр. Этот метод иногда называют прямым хешированием, поскольку индекс ячейки памяти определяется непосредственно по заданному элементу. Когда пользователь вводит формулу для ячейки, то эта ячейка /которая задается своим обозначением/ задает индекс массива указателей "sheet". Индекс определяется по обозначению ячейки путем его преобразования в число с помощью функции FindIndex. Вставка осуществляется с помощью следующей процедуры:
{ эта функция определяет индекс указанной ячейки }
function FindIndex(i: CellPointer): integer;
var
loc,temp,code:integer;
t:str9;
begin
loc := ord(i^.CellName[1]);
t := copy(i^.CellName,2,9);
val(t,temp,code);
loc := loc+(temp*20);
find := loc;
end; { конец функции поиска индекса }
procedure Store(New: CellPointer); var loc:integer; begin loc := FindIndex(New); if loc>10000 then WriteLn('Location out of bounds') else sheet[loc] := New; end; { конец процедуры вставки }
Поскольку каждая ячейка имеет уникальное обозначение, она будет иметь также уникальный индекс. Поскольку используется стандартная кодировка символов, указатель каждого элемента будет правильно помещен в массив. Если вы сравните эту процедуру с вариантом для связанного списка, то вы обнаружите, что она значительно короче и проще.
Функция удаления также выглядит короче. При вызове этой функции задается индекс ячейки и возвращается указатель элемента. Кроме того, освобождаемая память возвращается системе:
{ удаление ячейки из массива }
procedure Delete(r_cell: CellPointer);
var
loc:integer;
begin
loc := FindIndex(r_cell);
if loc>10000 then WriteLn('Cell out of bounds')
else
begin
Dispose(r_cell);
sheet[loc]:=nil;
end;
end; { конец процедуры удаления }
Если вы сравните эту процедуру с версией, использующей связанный список или дерево, то обнаружите, что она значительно проще и выполняется быстрее.
Следует помнить, что сам массив указателей требует некоторого дополнительного расхода памяти под каждую ячейку. В некоторых случаях это является серьезным ограничением.
ХЕШИРОВАНИЕ
Хешированием называется процесс выделения элемента индексного массива непосредственно по информации, которая содержится в массиве. Полученный индекс называется хеш-адресом. Хеширование обычно используется для уменьшения времени доступа к дисковым файлам. Однако тот же метод можно использовать для реализации разреженных матриц. В приводимом ниже примере используется процедура, где применяется специальная форма хеширования, называемая прямым индексированием. При прямом индексировании каждому ключу соответствует одна и только одна ячейка. (Т.е. хеширование дает уникальный индекс для каждого ключа. Однако следует заметить, что применение массива указателей не обязательно требует использования прямой индексации; просто для решения данной задачи такой подход является очевидным).
Из предыдущего примера по электронной матрице ясно, что даже в особых случаях не все ячейки будут использованы. Предположим, что в большинстве случаев не более десяти процентов потенциальных ячеек будет действительно использовано. Это значит, что логический массив с размерами 26х100 (2600 ячеек) потребует в действительности иметь память только под 260 элементов. Следовательно, потребуется иметь физический массив как максимум на 260 элементов. Тогда встает следующая задача: как логический массив отобразить на физический массив и как осуществлять к нему доступ? Ответ заключается в использовании списка индексов хеширования.
Когда пользователь вводит формулу в электронную матрицу (логический массив), адрес ячейки, задаваемый ее обозначением, используется для поручения индекса небольшого физического массива. Предположим, что переменная "sheet" является физическим массивом. Индекс определяется на основе обозначения ячейки путем его преобразования в число, как было сделано в примере с массивом указателей. Затем это число делится на десять для получения начальной точки входа в массив. (Следует помнить, что для вашего примера физический массив составляет только десять процентов от логического массива). Если ячейка с этим индексом свободна, то в нее помещается логический индекс и значение. В противном случае возникает конфликт. Конфликт случается при получении во время хеширования двух одинаковых ключей. В этом случае полученный индекс будет соответствовать одному элементу физического массива. Следовательно, в массиве "sheet" делается поиск свободного элемента. Когда свободный элемент найден, в него помещается информация, а указатель на это место будет помещен в исходный элемент. Это иллюстрируется на рис.3.
Для поиска элемента в физическом массиве при заданном индексе логического массива сначала делается преобразование логического индекса в адрес, полученный посредством хеширования, и затем делается проверка физического массива на наличие в элементе с этим индексом требуемого значения. Если сравнение выполняется удачно, то информация найдена. В противном случае следует пройти по цепочке индексов до тех пор, пока не будет найдено нужное значение или пока не будет обнаружен конец цепочки.
Для того, чтобы понять, как эту процедуру можно применить к программе электронной таблицы сначала определим в качестве физического массива следующий массив записей:
const SIZE = 260; type str9 = string[9]; str128 = string[128]; cell = record CellName: str9; formula: str128; next: integer; end; var sheet:array[0..SIZE] of cell; name: cell;
Таблица
Индекс Знач. След. Индекс в таблице
-------T------T------
A1 ¦ A1 ¦ 100 ¦ 1 ¦0
+------+------+------+
A2 ¦ A2 ¦ 200 ¦ 3 ¦1
+------+------+------+
B19 ¦ B19 ¦ 50 ¦ -1 ¦2
+------+------+------+
A3 ¦ A3 ¦ 300 ¦ -1 ¦3
+------+------+------+
¦ -1 ¦ 0 ¦ -1 ¦4
+------+------+------+
¦ -1 ¦ 0 ¦ -1 ¦5
+------+------+------+
D2 ¦ D2 ¦ 99 ¦ -1 ¦6
+------+------+------+
¦ -1 ¦ 0 ¦ -1 ¦7
+------+------+------+
¦ ¦ ¦
¦ ¦
¦ ¦
¦ ¦
¦ ¦ ¦
+------+------+------+
¦ -1 ¦ 0 ¦ -1 ¦2597
+------+------+------+
¦ -1 ¦ 0 ¦ -1 ¦2598
+------+------+------+
¦ -1 ¦ 0 ¦ -1 ¦2599
L------+------+-------
Предполагается, что в ячейке A1 значение 100, в A2 значение
200, в A3 - 300, в B19 - 50, а в D2 - 99.
Рис.3. Пример хеширования.
Перед использованием этот массив должен быть инициализирован. Приводимая ниже процедура используется для установки поля обозначения ячейки на значение "empty" (пусто) для указания на отсутствие элемента. Значение -1 в поле следующего индекса означает конец цепочки индексов хеширования.
{ инициализация физического массива }
procedure InitSheet;
var
t:integer;
begin
for t := 0 to SIZE do
begin
sheet[t].CellName := 'empty';
sheet[t].next:= -1;
end;
end; { конец процедуры инициализации физического массива }
В процедуре вставки делается обращение к функции HashIndex для вычисления индекса хеширования и помещения его в массив "sheet". Следует отметить, что если непосредственно полученное значение индекса хеширования указывает на занятую ячейку, то в процедуре выполняется поиск первого свободного места. Это делается путем просмотра цепочки индексов хеширования до тех пор, пока не будет обнаружена первая свободная ячейка. Когда свободная ячейка найдена, то делается запоминание значения логического индекса и значения элемента массива. Значение логического индекса требуется сохранить, поскольку он требуется при новом обращении к этому элементу.
{ вычисление индекса хеширования и вставка значения элемента }
function HashIndex(i:str9):integer;
var
loc, temp, code:integer
t :str9;
begin
loc := ord(i[1]-ord('A');
t := copy(i,2,9)
val(t, temp, code)
HashIndex := (loc*26+temp) div 10;
end;
{ выполнение действительной вставки значения элемента }
procedure Store(New:Cell);
var
loc, i:integer;
begin
loc := HashIndex(New.Cellname);
if loc>SIZE then Writeln('Location out of bounds')
else
begin
if ((sheet[loc].Cellname = 'empty') or
(sheet[loc].Cellname = New.Cellname)) then
begin
sheet[loc].Cellname = New.Cellname;
sheet[loc].formula = New.formula;
end else { поиск свободной ячейки }
begin
{ сначала просмотр до конца всей цепочки существующих индексов}
while(sheet[loc].next <>-1) do
loc := sheet[loc].next;
{ теперь поиск свободной ячейки }
i := loc;
while ((i<SIZE) and (sheet[loc].Cellname='empty'))
do i := i+1;
if(i = SIZE) then
begin
Writeln('cannot plase in hash array');
end else
begin { поместить значение в свободную ячейку и обновить цепочку }
sheet[i].Cellname = New.Cellname;
sheet[i].formula = New.formula;
sheet[loc].next := i; { обеспечение связи в цепочке }
end;
end;
end;
end; { конец процедуры вставки }
При поиске значения элемента сначала вычисляется индекс хеширования и делается проверка на равенство логического индекса, который содержится в физическом массиве, и искомого логического индекса. Если они совпадают, то в результате выдается этот индекс хеширования. В противном случае делается просмотр цепочки индексов до обнаружения требуемого значения или до обнаружения значения - 1 в поле ссылки на следующий элемент. Последняя ситуация возникает при отсутствии требуемого элемента в физическом массиве. Ниже приводится функция, выполняющая эти действия:
{ поиск физического адреса ячейки }
function Find(cname:cell):integer;
var
loc:integer;
begin
loc := FindIndex(cname.CellName);
while((sheet[loc].CellName>cname.CellName) and
(loc <> -1)) do loc:=sheet[loc].next;
if(loc = -1) then
begin
WriteLn('Not found');
Find := -1;
end else Find := loc;
write('loc is'); writeLn(loc);
end; { конец функции поиска }
Следует иметь в виду, что описанная схема хеширования очень проста и на практике приходится применять более сложные схемы хеширования. Например, при возникновении конфликта очень часто используют вторичное и третичное хеширование прежде, чем воспользоваться просмотром цепочки индексов хеширования. Однако, основные принципы хеширования остаются неизменными.
Анализ хеширования
При хешировании в лучшем случае (который встречается достаточно редко) каждый полученный хеш-функцией физический индекс является уникальным и время доступа приближается к времени прямого индексирования. Это значит, что цепочка индексов хеширования не создается и все операции поиска по существу являются операциями прямого поиска. Однако это случается редко, поскольку требуется, чтобы логический индекс равномерно распределялся в пространстве логических индексов. В худшем случае (который также редок) схема хеширования вырождается в схему поиска в связанном списке. Это будет в том случае, когда все полученные с помощью хеш-функции значения логических индексов будут равны. В среднем случае, который на практике встречается чаще всего, время поиска любого конкретного элемента посредством хеширования соответствует времени прямого индексирования, поделенного на некоторую константу, которая пропорциональна средней длине цепочки индексов хеширования. Самым существенным при использовании метода хеширования для реализации разряженной матрицы является обеспечение равномерности распределения физических индексов, чтобы не возникало длинных цепочек. Кроме того, метод хеширования очень хорошо использовать в тех случаях, когда известно какое максимальное число элементов действительно потребуется.
Выбор метода реализации разряженных матриц
При выборе связанного списка, двоичного дерева или массива указателей в качестве основы реализации разряженное матрицы следует учитывать эффективность использования оперативной памяти и время доступа.
Если разряженность очень большая, то память наиболее эффективно будет использоваться при применении связанного списка и двоичного дерева, поскольку в данном случае в памяти будут располагаться только требуемые элементы. Связи требуют небольшого дополнительного расхода памяти и обычно на расход памяти влияют незначительно. При использовании массива указателей необходимо предусмотреть место для указателя вне зависимости от наличия элемента. Здесь необходимо предусмотреть не только размещение в памяти всего массива указателей, но обеспечить память для других целей, определяемых конкретной задачей. В одних случаях это вызовет серьезные трудности, хотя в других случаях этих трудностей может не быть. Обычно приходится делать расчет требуемой памяти, чтобы понять, достаточно ли ее будет для вашей программы.
Метод хеширования занимает промежуточное место между методом, построенным на базе массива указателей, и методом, построенным на базе связанного списка или двоичного дерева. Хотя в данном случае требуется размещение в памяти всего физического массива, несмотря на то, что часть элементов не будет использована, его размеры все же будут меньше размеров массива указателей, для которого требуется предусмотреть, по крайней мере, один указатель для каждого логического элемента.
Однако при почти полном заполнении массива память будет использоваться более эффективно, когда применяется массив указателей. В связанных списках в двоичных деревьях, как правило, используется два указателя, в то время как массив указателей требует только одного указателя на каждый элемент. Например, полный массив из тысячи элементов, когда каждый указатель занимает два байта, потребует для реализации связанного списка или двоичного дерева 4000 байт для хранения указателей. Для массива указателей в этом случае потребуется 2000 байт, т.е. экономия составляет 2000 байт.
Наименьшее время доступа обеспечивает подход с применением массива указателей. Как в примере с электронной таблицей этот метод часто обеспечивает простой доступ к массиву указателей и просто обеспечивается связь с разреженной матрицей. Этот метод обеспечивает доступ к элементам разреженной матрицы почти со скоростью работы обычного массива. Поиск в связанном списке осуществляется очень медленно, поскольку здесь выполняется последовательный просмотр элементов списка. Даже при добавлении данных в связанный список, обеспечивающих более быстрый поиск элементов, поиск будет выполняться медленней, чем прямой доступ к элементам массива указателей. При использовании двоичного дерева быстродействие повышается, но все же оно меньше, чем при прямом доступе к элементам массива указателей.
При правильном выборе алгоритма хеширования этот метод часто дает лучшее время доступа, чем время доступа при использовании двоичных деревьев. Однако он никогда не достигнет быстродействия метода массива указателей.
Если возможно применение метода массива указателей, то этот метод является наилучшим из-за очень хорошего быстродействия. Однако, если решающее значение имеет эффективность использования памяти, то остается использовать лишь связанный список или двоичное дерево.
БУФЕРИЗАЦИЯ
При использовании разряженной матрицы вместо обычных переменных можно применять динамическое выделение памяти под матрицу. Пусть, например, имеется два процесса А и В, выполняющиеся в одной программе. Предположим, что процесс А требует при работе 60% доступной памяти, а при работе процесса В требуется 55% памяти. Если в процессе А и в процессе В память будет выделяться с помощью локальных переменных, то процесс А не сможет обратиться к процессу В, а процесс В не сможет обратиться к процессу А, поскольку потребуется более 100% памяти. Если процесс А не обращается к процессу В, то никаких трудностей не будет. Трудности появятся при попытке процесса А обратиться к процессу В. Выход из этого положения заключается в динамическом выделении памяти и для процесса А и для процесса В с освобождением памяти перед обращением одного процесса к другому процессу. Другими словами, если при выполнении каждого процесса, А и В, требуется более половины имеющейся доступной памяти и процесс А обращается к процессу В, то должно использоваться динамическое распределение памяти. В этом случае процессы А и В будут получать в свое распоряжение память, когда она им действительно потребуется.
Предположим, что при выполнении некоторой программы, использующей две указанные ниже функции, остается 100 000 байт неиспользованной памяти.
procedure B; forward;
procedure A;
var
a:array[1..600000] of char;
.
.
.
begin
.
.
.
B;
.
.
.
end;
procedure B;
var
b:array[1..55000] of char;
begin
.
.
end;
Здесь каждый из процессов А и В имеет локальные переменные, на которые расходуется более половины имеющейся доступной памяти. В данном случае нельзя будет выполнить процесс В, поскольку памяти недостаточно для выделения 55 000 байт под локальный массив "в".
В подобных случаях трудности часто оказываются непреодолимыми, но в некоторых случаях кое-что сделать можно. Если процесс А не требует сохранения содержимого массива "а" при выполнении процесса В, то процессы А и В могут совместно использовать один участок памяти. Это можно обеспечить динамическим выделением памяти под массивы А и В. Процесс А перед обращением к процессу В должен освободить память и затем вновь ее получить после завершения процесса В. Программа должна иметь следующую структуру:
procedure B; forward;
procedure A;
var
a:^array[1..600000] of char;
begin
New(a);
.
.
.
Dispose(a); { освобождение памяти для процесса В }
B;
New(a); { новое выделение памяти }
.
.
.
Dispose;
end;
procedure B;
var
b:^array[1..55000] of char;
begin
New(b);
.
.
.
Dispose(b);
end;
При выполнении процесса В существует только указатель "а".
Оптимальное использование доступной памяти
Если вы являетесь профессиональным программистом, то вам возможно приходилось сталкиваться с трудностями, возникающими когда размер доступной памяти заранее неизвестен. Эти трудности возникают при разработке программы, определенные характеристики которой зависят от размера памяти некоторых или всех ЭВМ, где она будет выполняться. Примерами таких программ являются программы управления электронными таблицами, программы обработки списков почтовых корреспонденций и программы сортировки. Например, программа внутренней сортировки, способная отсортировать 10 000 адресов в ЭВМ с памятью 256К, сможет отсортировать лишь 5 000 адресов в ЭВМ с памятью 128К. Если эту программу предполагается использовать на ЭВМ, размер памяти которой заранее неизвестен, то трудно выбрать оптимальный размер фиксированного массива для хранения сортируемой информации: либо программа не будет работоспособна для ЭВМ с малой памятью, либо программа будет рассчитана на худший случай и нельзя будет воспользоваться дополнительной памятью, когда она имеется. Выход из этого положения заключается в динамическом выделении памяти.
Подобные трудности и их решение хорошо можно проиллюстрировать на примере программы редактирования текста. Большинство текстовых редакторов не рассчитаны на использование фиксированного числа символов. Напротив, они используют всю память ЭВМ, которая идет на хранение текста, введенного пользователем. Например, при вводе каждой строки делается выделение памяти и достраивается список строк. При удалении строки память возвращается к системе. Для реализации такого текстового редактора может использоваться следующая запись для каждой строки:
LinePointer = ^Line;
str80 = string[80];
Line = record
next: str80; { для хранения каждой строки }
num: integer;
next: LinePointer; {указатель на следующую строку}
prior: LinePointer; {указатель на предыдущую запись }
end;
Для простоты в этом случае для каждой строки выделяется память под 80 символов. На практике будет выделяться память под точное число символов в строке и изменение строки потребует дополнительных затрат. В элементе "num" содержится номер каждой строки текста. Это позволяет использовать стандартную функцию "DLS_Store" для создания и поддержки текстового файла в виде упорядоченного списка с двойной связью.
Ниже приводится полная программа для простого текстового редактора. Он обеспечивает вставку и удаление любых строк с указанием номера строки. Он позволяет также просматривать текст и помещать его на диск.
В целом работа текстового редактора строится на базе применения упорядоченного связанного списка строк текста. В качестве ключа сортировки используется номер строки. Указывая начальный номер строки можно не только легко делать нужные вставки в текст, но также легко можно удалить текст. Единственной необычной функцией является функция "Patchup", которая перенумеровывает строки текста, когда этого требуют операции вставки и удаления.
В этом примере размер текста, который может размещаться в редакторе, зависит от доступной пользователю памяти. Таким образом, этот редактор будет автоматически использовать дополнительную память и не потребует перепрограммирования. Возможно, это является самым важным достоинством динамического распределения памяти.
Возможности приводимой программы очень ограничены, однако она обеспечивает основные функции текстового редактора. Эту программу можно усовершенствовать и получить текстовый редактор с требуемыми возможностями.
{ очень простой текстовый редактор }
program TextEd;
type
str80 = string[80];
LinePointer = ^Line;
line = record
text: str80;
num: integer;
next: LinePointer; {указатель на следующую строку}
prior: LinePointer; {указатель на предыдущую запись }
end;
DataItem = line;
filType = file of line;
var
text: filtype;
start, last: LinePointer;
done: boolean;
iname: str80;
{ возвращает выбранную пользователем функцию }
function MenuSelect: char;
var
ch: char;
begin
WriteLn('1. Enter text');
WriteLN('2. Delete a line');
WriteLn('3. Display the file');
WriteLn('4. Save the file');
WriteLn('5. Load the file');
WriteLn('6. Quit');
repeat
WriteLn;
Write('Enter your choice: ');
ReadLn(ch); ch := UpCase(ch);
until (ch>='1') and (ch<='6')
MenuSelect := ch;
end;{ конец выбора по меню }
{ поиск заданной строки и выдача указателя на нее }
function Find(num: integer): LinePointer;
var
i: LinePointer;
begin i:= start;
find := nil;
while (i<>nil) do begin
if lnum=i^.num then find :=i;
i := i^.next;
end;
end;
{ формирование номеров строк при вставке или удаления из текста }
procedure PatchUp(lnum, incr: integer);
var
i:LinePointer;
begin
i := Find(lnum)
while (i<>nil) do begin
i^.num := i^.num +incr;
i := i^.next
end:
end;
{ упорядоченная вставка строк в текст }
function DLS_Store(info, start: LinePointer;
var last: LinePointer): LinePointer;
var
old, top: LinePointer;
done: boolean;
begin
top := start;
old := nil;
done := FALSE;
if start = nil then begin { первый элемент списка }
info^.next := nil;
last := info;
info^.prior :=nil;
DLS_Store := info;
end else
begin
while (start<>nil) and (not done) do
begin
if start^.num < info^.num then
begin
old := start;
start := start^.next;
end else
begin { вставка в середину }
if old <>nil then
begin
old^.next := info;
info^.next := start;
start^.prior := info;
info^.prior := old;
DLS_Store := top; { сохранение начала }
done := TRUE;
end else
begin
info^.next := start;{новый первый элемент }
info^.prior := nil;
DLS_Store := info;
done := TRUE;
end;
end;
end; { конец цикла }
if not done then begin
last^.next := info;
info^.next := nil;
info^.prior := last;
last := info;
DLS_Store := top; { сохранение начала }
end;
end;
end; { конец функции DLS_Store }
{ удаление строки текста }
function DL_Delete(start: LinePointer
key: str[80]:) LinePointer
var
temp, temp2: LinePointer
done: boolean;
begin
if star^.num = key then begin { первый элемент списка }
DL_Delete := start^.next;
if temp^.next <> nil then
begin
temp := start^.next;
temp^.prior := nil;
end;
dispose(start);
end else
begin
done := FALSE;
temp := start^.next;
temp2 := start;
while (temp <> nil) and (not done) do
begin
if temp^.num = key then
begin
temp2^.next := temp^.next;
if temp^.next = <> nil then
temp^.next^.prior := temp2
done := TRUE
last := temp^.prior
dispose(temp);
end else
temp2 := temp;
temp := temp^.next;
end;
end;
DL_Delete := start; { начало не изменяется }
if not done then Writeln('not found');
else PatchUp(key+1,-1);
end;
end; { конец функции DL_Delete }
{ подсказка пользователю для ввода номера удаляемой строки }
procedure Remove;
var
num:integer;
begin
Writeln('Enter line to delete: ');
Readln(num);
start := DL_Delete(start,num);
end; { конец процедуры удаления }
{ ввод строк текста }
procedure Enter;
var
info: LinePointer;
done: boolean;
begin
done := FALSE;
Write('Enter starting lnie number: ');
Readln(num);
repeat
new(info) { получить новую запись }
info^.num := num;
Write(info^.num,':')
Readln(info^.text);
if Length(info^.text = 0 then done := TRUE
else begin
if Find(num)<> nil then PatchUp(num,1);
start := DLS_Store(info, start, last);
end;
num := num +1;
until done;
end; { конец ввода }
{ вывод файла на экран }
procrdure Display(start: LinePointer);
begin
while start <> nil do begin
Write(start^.num,':');
Writeln(start^.text);
start := start^.next
end;
Writeln;
end;
{ записать файл на диск }
procedure Save(var f:FilType; start: LinePointer):
begin
Writeln('saving file');
rewrite(f);
while start <> nil do begin
write(f,start);
start := start^.next;
end;
end;
{ загрузчика файла с диска и получение указателя на начало списка }
procedure Load(var f:FilType; start: LinePointer): LinePointer;
var
temp: LinePointer
begin
Writeln('load file');
reset(f);
while start <> nil do begin
temp := start^.next
dispose(start);
start := temp;
end;
start := nil; last := nil;
if not eof(f) then begin
begin
New(temp);
Read(f,temp^);
start := DLS_Store(temp, start, last);
end;
begin
start := nil; { сначала список пустой }
last := nil;
done := FALSE;
Write('Enter Filename: ');
Readln(filename);
Assign(text,filename);
repeat
case MenuSelect of
'1': Enter;
'2': Remove;
'3': Display(start);
'4': Save(text,start);
'5': start := Load(text);
'6': done := TRUE;
until done = TRUE;
end;
end.
ФРАГМЕНТАЦИЯ
Когда блоки доступной памяти располагаются между участками распределенной памяти, то говорят, что происходит фрагментация памяти. Хотя свободной памяти как правило бывает достаточно, чтобы удовлетворить запрос памяти, однако трудность заключается в том, что размеры отдельных участков свободной памяти недостаточны для этого, несмотря на то, что при их объединении получится достаточный объем памяти. На рисунке показано, как при определенной последовательности обращения к процедурам "New" и "Dispose" может возникнуть такая ситуация.
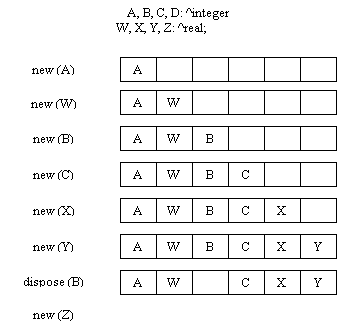 |
В некоторых случаях фрагментация уменьшается, так как функции динамического распределения памяти объединяют соседние участки памяти. Например, пусть были выделены участки памяти A,B,C,и D. Затем освобождаются участки B и C. Эти участки можно объединить, поскольку они располагаются рядом. Однако, если освобождаются участки B и D, то объединить их нельзя будет, поскольку между ними находится участок C который еще не освобожден:
 |
Так как B и D освобождены, а C занят, то может возникнуть вопрос: "Почему бы Паскалю не переслать содержимое C в D и затем объединить B и C?" Трудность заключается в том, что ваша программа не будет "знать", что это пересылка произошла.
Один из способов предотвращения большой фрагментации заключается в том, чтобы всегда выделять одинаковые участки памяти. В этом случае все освобожденные участки могут использоваться при любых последующих запросах на выделение памяти и таким образом будет использована вся свободная память. Если нельзя использовать всегда одинаковый размер выделяемых участков, то следует ограничиться только несколькими размерами. Иногда этого можно достигнуть путем объединения нескольких запросов на выделение небольших участков в один запрос на выделение одного большого участка памяти. Не следует для предотвращения фрагментации выделять больше памяти, чем действительно требуется, поскольку получаемая выгода не окупит потерь от неиспользованной памяти. Можно использовать другой подход к решению этой проблемы: при работе программы можно записывать информацию во временный дисковый файл, освободить всю память и затем считать информацию с диска в память. При считывании информации не будет создаваться никаких промежутков.
Динамическое распределение памяти и задачи искусственного интеллекта
Хотя Паскаль не является основным языком, который используется при решении задач искусственного интеллекта, его можно использовать и в этой области. Основной чертой многих программ из области искусственного интеллекта является наличие списка информационных элементов, который может расширяться программой автоматически по мере ее "обучения". В таком языке как Пролог, который считается основным языком искусственного интеллекта, поддержка списка обеспечивается автоматически. На языке Паскаль такие процедуры должны программироваться с применением связанных списков и механизма динамического распределения памяти. Хотя приводимый пример является очень простым, те же принципы применимы для разработки более сложных "разумных" программ.
Одну интересную область искусственного интеллекта составляют программы, работа которых напоминает поведение людей. Знаменитая программа "Элиза", например, ведет себя как психиатр. Совсем неплохо иметь программу, которая может разговаривать на любую тему. Ниже приводиться очень простая версия такой программы. В ней используются слова и их определения для ведения простого диалога с пользователем. Одной общей чертой всех программ искусственного интеллекта является связь информационного элемента с его смыслом. В этом примере слова связываются с их смыслом. Ниже описывается запись, предназначенная для содержания каждого слова, его определения, части речи и его дополнения:
type
str80 = string[80];
str30 = string[30];
VocabPointer = "тильда"vocab;
vocab = record
typ: char; { часть речи }
connotate: char; { дополнение }
word: str30; { само слово }
def: str80; { определение }
next: VocabPointer; { указатель на следующую запись }
prior: VocabPointer; { указатель на предыдущую запись }
end
В приводимой ниже программе делается ввод слова, его определения, типа слова и его дополнения типа "хорошо", "плохо" и "безразлично". Для поддержки такого словаря строится связанный список с использованием механизма динамического выделения памяти. Функция "DLS_Store" создает и поддерживает упорядоченный список слов словаря. После ввода нескольких слов в словарь можно начать диалог с ЭВМ. Например, вы можете ввести такое предложение, как "Сегодня хороший день". Программа будет просматривать предложения для поиска имени существительного, которое находится в словаре. Если оно найдено, то будет выдано замечание об этом имени существительном, зависящее от его смысла. Если программа встретит ей "неизвестные" слова, то она попросит ввести его и определить его характеристики. Для завершения диалога вводится слово "quit".
Процедура "Talk" является частью программы, которая поддерживает диалог. Вспомогательная функция "Dissect" выделяет из предложения слова. В переменной "sentence" содержится введенное вами предложение. Выделенное из предложения слово помещается в переменную "word". Ниже приводятся функции "Talk" и "Dissect":
{ поочередное выделение слов из предложения }
procedure Dissect(var s:str80;var w:str30);
var
t, x:integer;
temp:str80;
begin
t :=1;
while(s[t]=' ') do t := t+1;
x := t;
while(s[t]=' ') and (t<=Length(s)) do t := t+1;
if t<=Length(s) then t := t-1;
w := copy(s, x, t-x+1);
temp := s;
s := copy(temp,t+1,Length(s))
end;
{ формирование ответов на основании введенного пользователем предложения }
procedure Talk;
var
sentence: str80
word: str30
w: VocabPointer;
begin
Writeln('Conversation mode (quit to exit)');
repeat
Write(': ')
Readln(sentence)
repeat
Dissect(sentence,word);
w := Search(start, word);
if w <> nil then begin
if w^.type = 'n' then
begin
case w^.connotate of
'g': Write('I like ');
'b': Write('I do not like ');
end;
Writeln(w^.def);
end;
else Writeln(w^.def);
end;
else if word <>'quit' then
begin
Writeln(word,'is unknown.');
enter(TRUE);
end;
until Length(sentence) = 0;
until word = 'quit';
end;
Ниже приводится вся программа:
{ программа, которая позволяет вести очень простой диалог }
program SmartAlec;
type
str80 = string[80];
str30 = string[30];
VocabPointer = ^vocab
vocab = record;
typ: char; { часть речи }
connotate: char; { дополнение }
word: str80; { само слово }
def: str30; { определение }
next: VocabPointer; { указатель на следующую запись }
prior: VocabPointer; { указатель на предыдущую запись }
DataItem = vocab;
DataArray = array [1..100] of VocabPointer
filtype = file of vocab;
var
test: DataArray;
smart: filtype;
start, last:VocabPointer;
done: boolean;
{ возвращает функцию, выбранную пользователем }
function MenuSelect:char;
var
ch: char;
begin
Writeln('1. Enter words');
Writeln('2. Delete a word');
Writeln('3. Display the list');
Writeln('4. Search for a word');
Writeln('5. Save the list');
Writeln('6. Load the list');
Writeln('7. Converse');
Writeln('8. Quit');
repeat
Writeln;
Write('Enter your choice: ');
Readln(ch);
ch := UpCase(ch);
until (ch>='1') and (ch<='8')
MenuSelect := ch;
end;{ конец выбора по меню }
{ добавление элементов в словарь }
function DLS_Store(info, start: VocabPointer; var last: VocabPointer): VocabPointer;
var
old, top: VocabPointer;
done: boolean;
begin
top := start;
old := nil;
done := FALSE;
if start = nil then begin { первый элемент списка }
info^.next := nil;
last := info;
info^.prior :=nil;
DLS_Store := info;
end else
begin
while (start<>nil) and (not cone) do
begin
if start^.word < info^.word then
begin
old := start;
start := start^.next;
end else
begin { вставка в середину }
if old <>nil then
begin
old^.next := info;
info^.next := start;
start^.prior := info;
info^.prior := old;
DLS_Store := top; { сохранение начала }
done := TRUE;
end else
begin
info^.next := start;{новый первый элемент }
info^.prior := nil;
DLS_Store := info;
done := TRUE;
end;
end;
end; { конец цикла }
if not done then begin
last^.next := info;
info^.next := nil;
info^.prior := last;
last := info;
DLS_Store := top; { сохранение начала }
end;
end;
end; { конец функции DLS_Store }
{ удаление слова }
function DL_Delete(start: VocabPointerkey: str[80]:) VocabPointer
var
temp, temp2: VocabPointer
done: boolean;
begin
if star^.num = key then begin { первый элемент списка }
DL_Delete := start^.next;
if temp^.next <> nil then
begin
temp := start^.next;
temp^.prior := nil;
end;
dispose(start);
end else
begin
done := FALSE;
temp := start^.next;
temp2 := start;
while (temp <> nil) and (not done) do
begin
if temp^.word = key then
begin
temp2^.next := temp^.next;
if temp^.next = <> nil then
temp^.next^.prior := temp2
done := TRUE;
if last := temp then last := last^.prior
dispose(temp);
end else
begin
temp2 := temp;
temp := temp^.next;
end;
end;
DL_Delete := start; { начало не изменяется }
if not done then Writeln('not found');
end;
end; { конец функции DL_Delete }
{ удаление слова, заданного пользователем }
procedure remove;
var
name:str80;
begin
Writeln('Enter word to delete: ');
Readln(name);
start := DL_Delete(start,name);
end; { конец процедуры удаления слова, заданного пользователем}
{ ввод слов в базу данных }
procedure Enter;
var
info: VocabPointer;
done: boolean;
begin
done := FALSE;
repeat
new(info) { получить новую запись }
Write('Enter word: ');
Readln(info^.word);
if Length(info^.word)=0 then done := TRUE
else
begin
Write(Enter type(n,v,a): ');
Readln(info.typ);
Write(Enter connotation (g,b,n): ');
Readln(info.connotation);
Write(Enter difinition: ');
Readln(info.dif);
start := DLS_Store(info, start, last); { вставить запись }
end;
until done or one;
end; { конец ввода }
{ вывод слов из базы данных }
procrdure Display(start: VocabPointer);
begin
while start <> nil do begin
Writeln('word',start^.word);
Writeln('type',start^.typ);
Writeln('connotation',start^.connotation);
Writeln('difinition',start^.def);
Writeln;
start := start^.next
end;
end; {конец процедуры вывода }
{ поиск заданного слова }
function Search(start: VocabPointer; name: str80): VocabPointer;
var
done: boolean;
begin
done := FALSE
while (start <> nil) and (not done) do begin
if word = start^.word then begin
search := start;
done := TRUE;
end else
start := star^.next;
end;
if start = nil then search := nil; { нет в списке }
end; { конец поиска }
{ поиск слова, заданного пользователем }
procedure Find;
var
loc: VocabPointer;
word: str80;
begin
Write('Enter word to find: ');
Readln(word);
loc := Search(start, word);
if loc <> nil then
begin
Writeln('word',loc^.word);
Writeln('type',loc^.typ);
Writeln('connotation',loc^.connotation);
Writeln('difinition',loc^.def);
Writeln;
end;
else Writeln('not in list')
Writeln;
end; { Find }
{ записать словарь на диск }
procedure Save(var f:FilType; start: VocabPointer):
begin
Writeln('saving file');
rewrite(f);
while start <> nil do begin
write(f,start);
start := start^.next;
end;
end;
{ загрузить словарь с диска }
procedure Load(var f:FilType; start: VocabPointer): VocabPointer;
var
temp, temp2: VocabPointer
first: boolean;
begin
Writeln('load file');
reset(f);
while start <> nil do begin
temp := start^.next
dispose(start);
start := temp;
end;
start := nil; last := nil;
if not eof(f) then begin
New(temp);
Read(f,^temp)
start := DLS_Store(temp,start,last);
end;
Load := start;
end; { Load }
{ поочередное выделение слов из предложения }
procedure Dissect(var s:str80;var w:str30);
var
t, x:integer;
temp:str80;
begin
t :=1;
while(s[t]=' ') do t := t+1;
x := t;
while(s[t]=' ') and (t<=Length(s)) do t := t+1;
if t<=Length(s) then t := t-1;
w := copy(s, x, t-x+1);
temp := s;
s := copy(temp,t+1,Length(s))
end;
{ формирование ответов на основании введенного пользователем предложения }
procedure Talk;
var
sentence: str80
word: str30
w: VocabPointer;
begin
Writeln('Conversation mode (quit to exit)');
repeat
Write(': ')
Readln(sentence)
repeat
Dissect(sentence,wort);
w := Search(start, word);
if w <> nil then begin
if w^.type = 'n' then
begin
case w^.connotate of
'g': Write('I like ');
'b': Write('I do not like ');
end;
Writeln(w^.def);
end;
else Writeln(w^.def);
end;
else if word <>'quit' then
begin
Writeln(word,'is unknown.');
enter(TRUE);
end;
until Length(sentence) = 0;
until word = 'quit';
end;
begin
start := nil;
last := nil;
done := FALSE;
Assign(smart,'smart.dfd')
repeat
case MenuSelect of
'1': Enter(FALSE);
'2': Remove;
'3': Display(start);
'4': Find;
'5': Save(smart,start);
'6': start := Load(smart,start);
'7': Talk;
'8': done := TRUE;
end;
until done=TRUE;
end.